PQ Tree Algorithm
Nov 14, 2008
If you don't find programming algorithms interesting, this post is not for you.
In grad school I ran across an cool problem and an interesting algorithm to solve it. Your input is a grid of elements, lets say rows 1, 2, 3, 4, 5 and columns A, B, C, D, E. In addition, you are given a set of "rectangles" which each consist of a subset of the grid's rows and a subset of the grid's columns. Is there a way to arrange the grid by permuting it's rows and columns such that all the rectangles are present contiguously?
Imagine a rectangle consisting of rows 2 and 5 and columns A, C, and D. The grid must be arranged such that row (2, 5) are contiguous and columns (A, C, D) are contiguous. One rectangle is trivial, multiple rectangles is a challenge. Take a look at this figure which visualizes one of these grids with embedded rectangles.
I realized the 2D problem decomposes into two separate 1D problems. The rows can be arranged without caring about the columns and vice versa. Once you reduce the problem to 1D, it turns out that it is a problem known as the Consecutive Ones Problem. If all you want to do is find an valid ordering, there is even an algorithm to solve the problem. In my case, there was rarely a perfect ordering, so I had to extend the problem to find the best ordering for some definition of best (see this paper on the subject).
The PQ Tree Algorithm
That would be the end of the boring story, except I mentioned that there was a algorithm that solved the perfect ordering problem and it was well-studied. It turned out that despite it being well studied, it is poorly known and minimally referenced on the internet.
The paper that explained it, Testing for the consecutive ones property, interval graphs, and grapih planarity using PQ-tree algorithms, came out in 1976. This post describes the contents of that paper in some detail.
The algorithm is called the "PQ-Tree Algorithm". I picked up a copy of the paper in book-form from my local library. Surprisingly, the problem can be solved in linear time. It is quite an intricate algorithm. I think I recall spending 2 weeks doing nothing but implementing this algorithm.
Lets make sure that you know what the problem is first. I'll state it simpler than my above 2D problem:
Consecutive Ones Problem
Imagine that you are having a dinner party and are planning the seating arrangement. To simplify the problem, imagine your seating as a one-dimensional ordering of your guests: Sue > Fred > Tom > Rudy > Bob > ... You are trying to choose a seating arrangement that makes the most sense for your guests, and you have a number of constraints that apply to the problem. Each constraint is represented by a subset of your guests which you want to seat together (consecutively). So, if one constraint is that Sue, Fred, and Bob sit together, then there are certain permutations that are invalid and certain permutations that are valid:
Valid: Rudy > Sue >
Fred > Bob > Tom
Valid: Tom > Rudy >
Bob > Sue > Fred
Invalid: Tom > Bob
> Rudy > Fred > Sue
Furthermore, there may be many of these types of constraints, so perhaps you have (Sue, Fred, Bob) as one constraint and another might be (Sue, Bob, Tom). One possible solution would be given as:
Tom > Sue > Bob > Fred > Rudy
This is the crux of consecutive ones problem, although the consecutive ones problem is formulated a little differently: Given a binary matrix containing only ones and zeros, reorder the columns such that the ones in every row are consecutive. The image below illustrates the point:
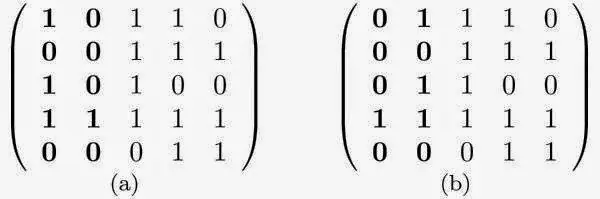
The matrix (a) can be transformed to the matrix (b) be rearranging only the columns in (a). The matrix (b) has the consecutive ones property (COP) in that the 1 values in each row are consecutive when read in order. The consecutive ones problem is: Given a matrix (a), determine if it can be converted into a matrix (b) by rearranging columns such that (b) has the consecutive ones property, and if so represent all valid orderings of the columns.
To see that this is the same as the guest seating problem, assign each guest to a column in matrix A. Each row represents one of the constraints we want to apply to our seating - the columns in that row containing 1's are the guests that we want to seat together.
Not all matrices can be transformed into a COP matrix. Similarly, some matrices can have many possible orderings.
PQ Tree
A PQ-tree is a data structure thatrepresents all possible solutions to the consecutive ones problem. It allows one to incrementally apply constraints (or rows in the matrix representation) and have a representation of all possible solutions at any point given all constraints applied so far.
A PQ-tree has 3 types of nodes:
- Leaf Nodes represent each element in the permuted set, for example in the matrix each column would be represented by a single leaf node. As with regular trees, leaf nodes have no descendents.
- P-nodes have 2 or more children of any node type.
- Q-nodes have 3 or more children of any node type.
All of the internal nodes of a PQ-tree are either P-nodes or Q-nodes. An unconstrained PQ-tree is a single P-node with direct child leaf node for each element in the permuted set.
A PQ-Tree represents all valid solutions to a COP problem. An in-order traversal of the leaves of the tree gives you one valid solution, and by reordering the children of P and Q nodes in a simple way, one can produce all possible valid solutions:
- For each P-node, all of it's children can be reordered in any order.
- For each Q-Node, the order of the children can be reversed.
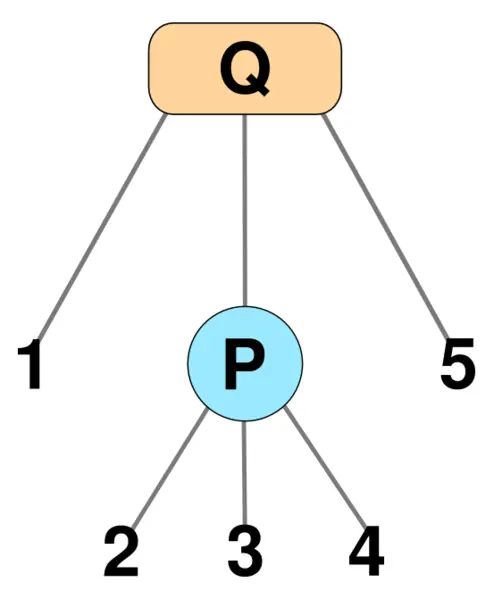
Take, for example, this PQ-tree diagram. One valid ordering from this PQ-tree is 1,2,3,4,5 given by an in-order traversal. If the children of the P-node were reordered as 4,2,3 we see another valid ordering is 1,4,2,3,5. Leaving the reordered children of the P-node, and reversing the order of the children of the Q-node, we construct another valid ordering of 5,3,2,4,1. The ordering of the leaves, read via an in-order traversal (aka: left to right), is called the PQ-tree's frontier.
PQ Tree Construction
In order to construct a PQ-tree for a given COP problem, a complex algorithm must be followed. First, auniversal PQ-tree must be constructed consisting of a single P-node at it's root with one child leaf node for each element in the COP permuted set.
The universal PQ-tree is incrementally modified by each constraint in the COP problem. A constraint is simply a set of leaves that must appear consecutively. The PQ Tree algorithm guarantees that any constraint can be applied in O(n) operations where n is the size of the constraint set. This ultimately means that the PQ Tree algorithm is O(n) in the number of elements in the permuted set plus the number of elements in all of the applied reductions.
When applying a constraint, we consider each leaf node in the constraint as full and each leaf node not in the constraint as empty. We also consider any internal node as full whose children are also all full and we consider any internal node as empty whose children are also all empty. Full and empty nodes are displayed in diagrams below as black and grey shapes respectively. An internal node which has both full and empty children is considered partial. Partial nodes appear in the diagrams below as both black and grey. The smallest subtree containing all of the full nodes in the tree is considered the pertinent subtree and it's root (note: may not be the root of the whole tree) is considered the pertinent root.
Applying a constraint is known as a reduction. A reduction consists of two phases: bubble and reduce.
Bubble Phase
The bubble phase simply marks all of the nodes in the pertinent subtree as full or partial and provides a count for each node of the number of pertinent children it has. In order to do this efficiently, it works bottom up, and never looks at any of the nodes outside of the pertinent subtree. This requires that children point to their parent, but the children frequently change parents during a reduction. In order to maintain the linear time bounds, only children of P-nodes and endmost children of Q-nodes will have accurate parent pointers at any given time. The endmost children of a Q-node are those children which only have one immediate sibling, they are at the ends of the ordering.
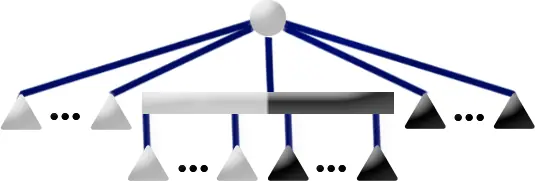
Children of Q-nodes which are interior will use their endmost-sibling's pointer and will remember this new pointer during the bubble phase. When an interior Q-node is encountered, we check to see if either of it's siblings have valid parent pointers. If not, that node becomes blocked. In a later step, when processing a sibling of this blocked node who has received a valid parent pointer, this blocked node is passed a parent pointer and becomes unblocked. If at the end of the bubble phase, there is still one consecutive set of blocked interior nodes, as would happen in the case of Pattern Q3 below, a "pseudo node" with no parent becomes the parent of that block which gets removed in the reduce phase.
Reduce Phase
The reduce phase, which runs after the bubble phase uses a queue to process nodes. Each leaf is first inserted into the queue. Then, while the queue is not empty, an element is dequeued and processed and it's parent gets added to the queue if the parent is part of the pertinent subtree. The processing for each node follows one of a set of 10 patterns. Each pattern has a template which determines whether or not the pattern matches, and a replacement, which describes the processing that must be done to exit the pattern. If none of the patterns match, the entire reduction is impossible for the given tree and fails. This means that there is no COP solution given the constraints applied so far. Each of the patterns is described in more detail below:
Reduce Patterns
Leaf Pattern
The leaf pattern is simple - it matches all leaves in the reduction and it's replacement simply marks the leaf as full.
P1 Pattern

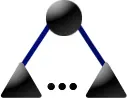
Template: The P1 template matches if the current node is a P-node
whose children are full nodes:
Replacement: Mark the current node as full.
P2 Pattern
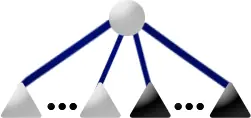
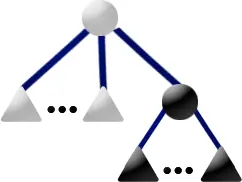
Template: The P2 template matches if the current node is a P-node
with both full and empty children and the current node is at the root of
the pertinent subtre, that is all full leaves are descendants of the
current node:
Replacement: Move the full children out of the current node and
into a new full P-node which becomes one of the current node's children.
P3 Pattern
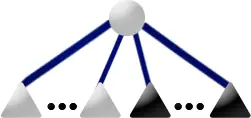
Template:: The P3 Template matches if the current node is a P-node
with both full and empty children and if the current node is not at the
root of the pertinent subtree (there exist full leaves which are not
descendants of the current node).
Replacement:
- Move the full children out of the current node C and into a new full P-node F.
- Move the empty children out of the current node and into a new empty P-node E.
- If either E or F would have had only one child, do not create a new P-node, simply assign that one child as the E or F node respectively.
- Replace C with a new Q-node R and set R's children as E and F.
P3's replacement is unique in that it's structure cannot ever be found within a PQ Tree between reductions. One of the rules describing a Q-node is that it must have more than 2 children, otherwise a P-node/Q-node distinction is ambiguous. Hence P3's replacement is considered a "pseudonode" as it will not survive in it's current form in later steps in the current reduction phase. When the replacement's parent is processed (and P3 only matches if it has a pertinent parent), the pseudonode will be transformed into a subtree containing only valid nodes.
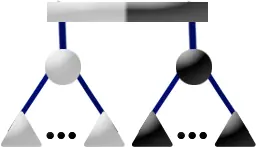
P4 Pattern
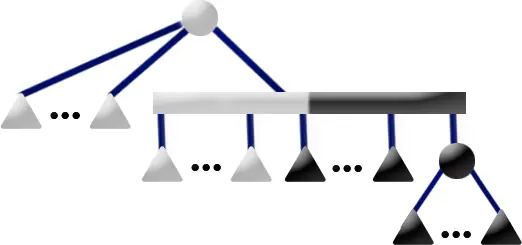
Template: The P4 Template matches if the current node is a P-node with 1 partial child and if the current node is at the root of the pertinent subtree, that is all full leaves are descendants of the current node. The current node may have any number of full and empty children. Replacement: Move the full children out of the current node C and into a new full P-Node F. F then becomes a child of C's only partial child P. F is added to P's children as a new endmost child, whose sibling is the former endmost child of P which is also full.
P5 Pattern
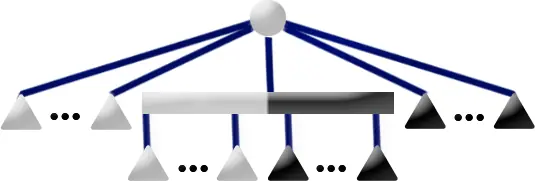

Template: The P5 Template matches if the current node is a P-node with 1 partial child and if the current node is not at the root of the pertinent subtree (there exist full leaves which are not descendants of the current node). The current node may have any number of full and empty children. Replacement: Move the full children out of the current node C and into a new full P-node F. Move the empty children out of the current node and into a new empty P-node E. If either E or F would have had only one child, do not create a new P-node, simply assign that one child as the E or F node respectively. Let P represent the only partial child of C. E becomes the new empty child of P, E is added to P's children as a new endmost child, whose sibling is the former empty endmost child of P. F becomes the new full child of P, F is added to P's children as a new endmost child, whose sibling is the former full endmost child of P.
P6 Pattern
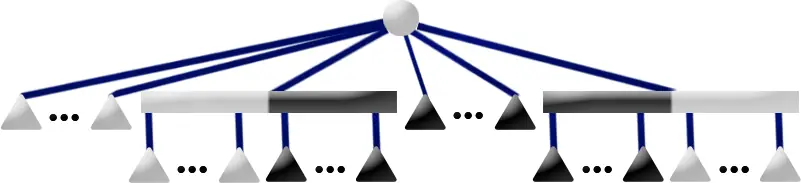
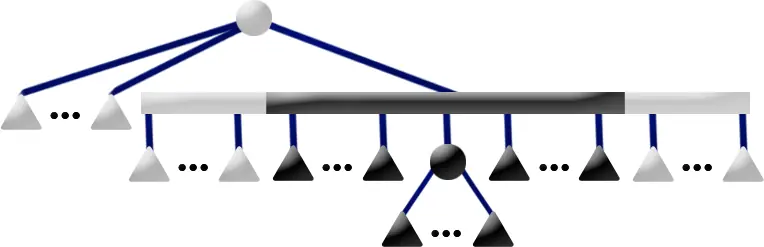
Template: The P6 Template matches if the current node is a P-node
with exactly 2 partial children and any number of full or empty children.
Replacement: Move the full children out of the current node C and
into a new full P-node F. If either F would have had only one child, do
not create a new P-node, instead assign that one child as the node denoted
by F. Let P1 and P2 represent partial children of C.
Add F to P1 as a sibling of P1's full endmost child.
Add as F's other sibling P2's full endmost child. Consider
P1's endmost child pointer that previously pointed to it's full
child, re-point that at P2's empty endmost child. Discard
P2 as it is no longer needed since P1 now consumes
all of P2's children as well as any full children of C.
Q1 Pattern


Template: The Q1 Template matches if the current node is a Q-node
with only full children.
Replacement: Mark the current node as full.
Q2 Pattern


Template: The Q2 Template matches if the current node is a Q-node
with exactly one partial child and any number of full or empty children.
All of the full children must be consecutive and the partial child must be
consecutive at the end of the list of consecutive full children.
Replacement: Identify the only partial partial child P of the
current node C. Let PF be P's full endmost child and
PE be P's empty endmost child. Furthermore let, F be P's full
sibling and E be P's empty sibling. One of each of F's and E's siblings is
P. Replace P with PF as F's sibling and replace P with
PE as E's sibling. If P did not have an empty or a full
sibling, P's endmost child instead becomes C's endmost child. Now P's
children are also C's children, Delete P.
Q3 Pattern


Template: The Q3 Template matches if the current node is a Q-node
with exactly two partial children and any number of full or empty
children. All of the full children must be consecutive and immediately
between the two partial children.
Replacement: For each of the two partial children P of the current
node C, process them as follows. Let PF be P's full endmost
child and PE be P's empty endmost child. Furthermore let, F be
P's full or partial sibling and E be P's empty sibling. One of each of F's
and E's siblings is P. Replace P with PF as F's sibling and
replace P with PE as E's sibling. If P did not have an empty or
a full sibling, P's endmost child instead becomes C's endmost child. Now
P's children are also C's children, Delete P. Repeat for both partial
children P.
Applications
In In addition to solving the consecutive ones problem described above, PQ-Trees can be used to solve a class of related problems including interval graphs, or determining if a graph is planar. They have practical applications in areas such as genetics, road planning, or compression.
References
- Testing for the consecutive ones property, interval graphs, and planarity using PQ-tree algorithms by KS Booth, GS Lueker in Journal of Computational Systems Science, Vol. 13 (1976), pp. 335-379.
My Contributions
I implemented this algorithm in grad school. My implementation then was functional but not high quality, and it was embedded in a larger library.
I've created a project up at github which tracks the code: PQ Tree Algorithm Implementation.
If you found this useful, I encourage you to drop me an email and let me know how you are using it.

Blog of Greg Grothaus.
Software Engineer at Google. Outdoor adventurer type. Opinions expressed here are mine alone.